

Cómo perfeccionar un modelo LLM con tus textos: Parte 2 - Exploración de tus datos de texto sus datos textuales 🧠📚
¿Listo para llevar tus modelos de lenguaje al siguiente nivel? 🔥 En esta segunda entrega de cómo entrenar un modelo LLM con tus datos de texto, te mostraremos cómo explorar y analizar tus datos textuales antes de utilizarlos para perfeccionar un modelo de lenguaje (LLM). ¡La calidad de tu modelo dependerá de los datos que uses! 📝✨
Recuerda que este artículo es una traducción del post original de Ed Donner en su portal web.
¿Por qué es importante explorar tus datos? 🔍
Antes de lanzarte a entrenar un modelo, es crucial entender tus datos:
- ¿Qué temas cubren? 🌐
- ¿Son representativos de los resultados que deseas obtener? ✅
- ¿Tienen problemas como ruido, errores o sesgos? ⚠️
Explorar tus datos te ayudará a identificar patrones, limpiar inconsistencias y tomar decisiones informadas para crear un modelo robusto.
Esta es la siguiente entrega de mi guía para entrenar un modelo LLM con el historial de tus mensajes de texto, como hice durante las vacaciones con mis 240,000 mensajes. En este artículo, descubrirás más de lo que jamás quisiste saber sobre tus propios mensajes de texto… El post anterior está aquí.
En esta parte y la siguiente, limpiaremos y curaremos un conjunto de datos de documentos bien adaptados a la Generación de Lenguaje Natural. Esto puede no parecer la parte más emocionante del proceso, pero de hecho, disfruté mucho de esta etapa. Además, perfeccionar el formato de los datos resultó tener un impacto mucho mayor en los resultados que ajustar interminablemente los hiperparámetros.
Decidí realizar todo el trabajo de formateo de mis mensajes de texto localmente en mi portátil. Luego encripté los datos antes de subirlos a Hugging Face. Esto no debería ser estrictamente necesario, ya que Hugging Face mantiene los datos privados, pero quise tomar esta precaución adicional para proteger mis textos, y tú podrías querer hacerlo también.
Poniendo los datos en tus manos
Abre un Jupyter Notebook o Jupyter Lab en tu máquina local (por ejemplo, creando un entorno virtual y ejecutando pip install jupyterlab seguido de jupyter lab). Luego, prepara tu entorno para la acción:
# constants
MAX_LENGTH = 200 # The length of each chunk
DATA_NAME = "your-hf-username/messagesv1" # for uploading
ME = "Edward" # your name here!
base_model_name = "meta-llama/Llama-2-7b-chat-hf" # for the tokenizer
# installs
!pip install ipywidgets datasets cryptography torch transformers sentencepiece matplotlib wordcloud
# imports
import csv
import datetime
import random
from collections import Counter
import datasets
from cryptography.fernet import Fernet # to encrypt our texts
import tqdm
import torch
from transformers import AutoTokenizer
import matplotlib
import matplotlib.pyplot as plt
from wordcloud import WordCloud
%matplotlib inlineColoca las exportaciones CSV de iMazing en el directorio raíz de tu notebook y ejecuta esto, actualizándolo con tus nombres de archivo:
txts = []
filenames = ['all_text_messages.csv', 'all_whatsapp_messages.csv']
for filename in filenames:
with open(filename, newline='') as csvfile:
reader = csv.DictReader(csvfile, delimiter=',', quotechar='"')
txts.extend(reader)
print(f'Read in a total of {len(txts):,} messages')
# For me, this outputs: Read in a total of 266,337 messagesVale la pena tomarse un tiempo para analizar los datos e identificar problemas. Aquí hay uno que encontré y solucioné de inmediato:
INTRO = 'Messages to this chat and calls are now secured with end-to-end encryption' txts = [txt for txt in txts if txt['Text'] != INTRO] print(f'Now a total of {len(txts):,} messages') Los mensajes actualmente están en forma de diccionarios, y en este punto los convierto en objetos para mayor comodidad. Excluyo los mensajes de grupos y de personas que no están en mis contactos. Además, limpio un poco el texto, como reemplazar los dos puntos por punto y coma, ya que más adelante usaremos los dos puntos con un significado especial en los datos de entrenamiento.
class Message:
def __init__(self, chat_session, message_type, text, when):
self.name = chat_session
self.sender = self.name if message_type == 'Incoming' else ME
self.receiver = ME if message_type == 'Incoming' else self.name
self.text = text
self.when = datetime.datetime.strptime(when, '%Y-%m-%d %H:%M:%S')
self.massage_text()
def massage_text(self):
# Replace special characters used in our format for training
self.text = self.text.replace('\n',' ').replace(':',';').replace('#',';')
# Indicate if the message is an image
if self.text == '': self.text = '***'
def should_exclude(self):
return any(ch in self.name for ch in '+&,') or all(ch.isdigit() for ch in self.name)
# Create lists of messages
messages = [Message(t['Chat Session'], t['Type'], t['Text'], t['Message Date']) for t in txts]
messages = [m for m in messages if not m.should_exclude()]
print(f'A total of {len(messages):,} messages')
# For me, this outputs: A total of 242,230 messagesOrganizar los datos
Antes de proceder a entrenar el modelo LLM, ahora organizamos los mensajes en un diccionario, donde las claves son los nombres de las personas con las que estamos chateando. Los valores son listas de objetos de tipo Message, ordenados desde el mensaje más antiguo hasta el más reciente. Esto debería entrelazar mensajes de texto y mensajes de WhatsApp.
# Organize into dict with key = chat name, value = list of messages
chats = {}
for message in messages:
if message.name not in chats:
chats[message.name] = []
chats[message.name].append(message)
# Sort the chats by time
for message_list in chats.values():
message_list.sort(key = lambda m: m.when)
print(f'{sum([len(v) for v in chats.values()]):,} messages with {len(chats)} people')
# Gives me 242,230 messages with 472 peopleDecidí que necesitaba intercambiar al menos 20 mensajes de texto con alguien para que se incluyeran. Esto tuvo un efecto marginal en la cantidad de mensajes, pero un gran efecto en la cantidad de personas únicas. Definitivamente es algo con lo que se puede experimentar.
AT_LEAST = 20
chats = {name: messages for name, messages in chats.items() if len(messages)>=AT_LEAST}
print(f'{sum([len(v) for v in chats.values()]):,} messages with {len(chats)} people')
# Gives me 240,985 messages with 290 peopleInvestigar los datos
Aunque el objetivo sea crear nuestro modelo LLM, siempre es esencial examinar los datos para buscar tendencias y anomalías. En este caso, ¡también es muy interesante! Empecé por ver con qué frecuencia había enviado mensajes de texto a lo largo de los años. Adivina cuándo conocí a mi pareja...
# Prepare data
dates = [message.when for message in messages]
# Plot
fig, ax = plt.subplots(1, 1)
plt.title("How many texts I've sent over time")
ax.set_xlabel('Year')
ax.set_ylabel('How many texts');
ax.get_yaxis().set_major_formatter(matplotlib.ticker.FuncFormatter(lambda y, p: format(int(y), ',')))
_ = ax.hist(dates, bins=20, color='purple', rwidth=0.5)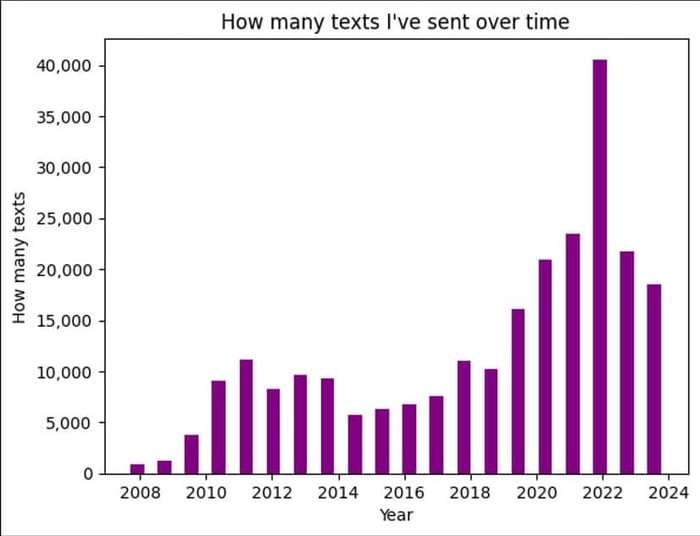
Y si tienes curiosidad por saber a quién le has enviado mensajes de texto con más frecuencia:
# Prepare data
counter = Counter(message.name for message in messages)
results = counter.most_common(40)
names, counts = zip(*results)
# Plot
fig, ax = plt.subplots(1, 1, figsize = (10, 5))
ax.set_ylabel('How many texts');
ax.get_yaxis().set_major_formatter(matplotlib.ticker.FuncFormatter(lambda y, p: format(int(y), ',')))
plt.xticks(range(len(names)), names, rotation='vertical')
_ = ax.bar(names, counts, color ='teal', width = 0.5)¡Éstos son mis resultados, con los nombres enmascarados!
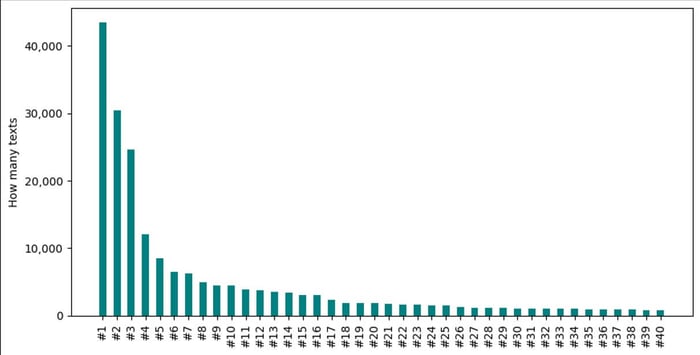
¡He dejado lo mejor para el final! Ahora vamos a crear una nube de palabras de mensajes para obtener algunas ideas. Para mi versión, me he limitado a las 50 palabras principales para evitar revelar algunos de mis desafortunados apodos... ¡pero es muy divertido investigar más allá de las 50 palabras! También puedes intentar filtrar los mensajes solo para ti o para chats con personas específicas, para ver cómo cambia el tono de tus conversaciones.
# Prepare data
text = ' '.join([message.text for message in messages])
# Alternatively - only my sent messages, or only chats with 1 person
# text = ' '.join([message.text for message in messages if message.sender==ME])
# text = ' '.join([message.text for message in chats['recipient name here']])
# Plot
wordcloud = WordCloud(max_font_size=60, max_words=50).generate(text)
plt.figure(figsize = (10, 10))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()¿Aún no estás inscrito en el curso completo?

Accede a todo el contenido del curso Ingeniería de LLMs e IA Generativa y domina las técnicas más avanzadas de IA generativa. ¡No pierdas esta oportunidad para transformar tu carrera profesional! 🎓
Apúntate al curso ahoraPreparación para la siguiente parte: los tokens
En la próxima publicación de cómo entrenar un modelo LLM con tus datos, comenzaremos a trabajar con tokens en lugar de texto. Si no estás familiarizado con la tokenización, este sería un excelente momento para ver el fantástico video de Jon Krohn que publiqué la semana pasada. Como preparación para la próxima publicación y poder llegar a entrenar un modelo LLM con tus datos, deberíamos investigar el Tokenizador que utiliza el modelo Llama 2.
tokenizer = AutoTokenizer.from_pretrained(base_model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"Podemos utilizar los métodos encode, decode y convert_ids_to_tokens para investigar cómo el texto se mapea a tokens y algunas de las peculiaridades de la tokenización.
tokens = tokenizer.encode('### Edward: hello me ### Edward: hi me')
print(tokens)
print(tokenizer.decode(tokens))
print(tokenizer.convert_ids_to_tokens(tokens))Al experimentar con las entradas, notarás algunas cosas:
- El tokenizador agrega un token de inicio de oración
<s>con valor 1. - Si cambias la entrada para poner cada mensaje en una nueva línea (como en '### Edward: hello me\n### Edward: hi me'), verás que el segundo
###se representa de manera diferente al primero (dividido en 2 tokens). Intenté estructurar los datos para evitar este tipo de inconsistencia. - Notarás que las etiquetas de prompt
<<SYS>> <</SYS>>y[INST] [/INST]no tienen tokens especiales; se tokenizan como cualquier otro texto. Me sorprendió esto, al igual que a otras personas en internet... aparentemente, el uso de estas etiquetas es solo una convención que se ha utilizado durante el entrenamiento.
La próxima vez en nuestra serie de cómo entrenar un modelo LLM, empaquetaremos nuestros mensajes de texto en conjuntos de datos, los encriptaremos y los subiremos a Hugging Face, listos para afinar nuestro modelo usando QLoRA. La próxima entrega de cómo entrenar un modelo LLM con tus datos está aquí.
¡Nos vemos en clase!


