
Agrupar textos en documentos
Comencé con el cuaderno Jupyter del artículo anterior. Luego creé una clase Document que representa un fragmento de textos con la misma persona. Este es el lenguaje natural que usaremos para entrenar nuestro modelo.
class Document:
def __init__(self, name, messages):
self.name = name
self.messages = messages
def to_text(self):
result = "<<SYS>>Escribe un mensaje de texto realista para el chat. Evita las repeticiones.<</SYS>>\n"
result += f"[INST]Escribe un chat entre Edward y {self.name}[/INST]\n"
result += " ".join(f"### {message.sender}: {message.text}" for message in self.messages)
return result
def token_len(self):
return len(tokenizer.encode(self.to_text()))Verás que el método to_text() crea una cadena que comienza con un prompt y es seguida por cada mensaje. Probé muchas, muchas variaciones y hice estos descubrimientos:
- Los prompts más cortos funcionaron bien; no es necesario proporcionar instrucciones detalladas. En mis versiones anteriores, intenté usar el prompt para ordenar estrictamente a la LLM que no se repitiera, pero hizo poca diferencia. Fue mucho más efectivo aplicar restricciones durante la generación del texto, lo que veremos más adelante.
- En teoría, la instrucción [INST] está destinada a estar dentro del prompt <<SYS>>. Descubrí que funcionaba mejor tener una tras otra. Tu experiencia puede variar.
- Experimenté mucho con el uso de ### y : para separar los mensajes, y si poner cada mensaje en una línea separada. El enfoque anterior pareció ser el que mejor funcionó para mí. Estoy bastante seguro de que hay espacio para mejorar los resultados refinando esta estructura. Si has encontrado algo mejor, ¡por favor avísame!
A continuación, escribí un trozo de código delicado para agrupar los chats en Documentos, donde cada Documento encaja dentro de 200 tokens y mete tantos textos con la misma persona como sea posible. Esto será perfecto para nuestro conjunto de datos.
documents = []
for name, message_list in tqdm.tqdm(chats.items()):
pointer = 0
while pointer < len(message_list):
size = 1
while pointer + size < len(message_list):
next_doc = Document(name, message_list[pointer:pointer+size+1])
if next_doc.token_len()>=MAX_LENGTH:
break
size += 1
document = Document(name, message_list[pointer:pointer+size])
documents.append(document)
pointer += size
print(f"{len(documents):,} documents")
# I get 26,104 documentsInvestigar los Documentos
Vamos a investigar los documentos para poder realizar el fine-tuning de un LLM con tus ellos:
data = [doc.to_text() for doc in documents]
lengths = [doc.token_len() for doc in documents]
counts = sum(d.count('###') for d in data)
print(f'Hay {counts:,} mensajes; promedio {counts/len(documents):.2} mensajes en cada uno de los {len(documents):,} documentos')
# Obtengo: Hay 240,985 mensajes; promedio 9.2 mensajes en cada uno de los 26,104 documentosNota al margen: puede que te preguntes por qué elijo 200 como la longitud máxima de la secuencia. La respuesta es profundamente insatisfactoria: fue un proceso de prueba y error, y 200 funcionó bien. Los tamaños más grandes ralentizaron el entrenamiento y provocaron problemas de memoria; los números más pequeños redujeron la calidad de los resultados. Tal vez 9 mensajes sea la longitud típica de mis conversaciones de texto. Si tienes chats de texto más sustanciales que yo, es posible que te vaya mejor con secuencias más largas.
Otra nota al margen rápida: es posible que notes que algunos documentos tienen más de 200 tokens, si el mensaje y el primer mensaje ya superan los 200. En ese caso, se truncará a 200 durante el entrenamiento del fine-tuning de un LLM con tus propios textos.
Podemos visualizar el tamaño de cada documento en el conjunto de datos, lo que ayuda a mostrar que nuestros textos se están empaquetando bastante bien en fragmentos de 200 tokens.
fig, ax = plt.subplots(1, 1)
ax.set_xlabel('Number of tokens in a document')
ax.set_ylabel('Count of documents')
ax.get_yaxis().set_major_formatter(matplotlib.ticker.FuncFormatter(lambda y, p: format(int(y), ',')))
l2 = [min(MAX_LENGTH+100,l) for l in lengths]
_ = ax.hist(l2, bins=range(0,MAX_LENGTH+50,10), color='darkorange', rwidth=0.5)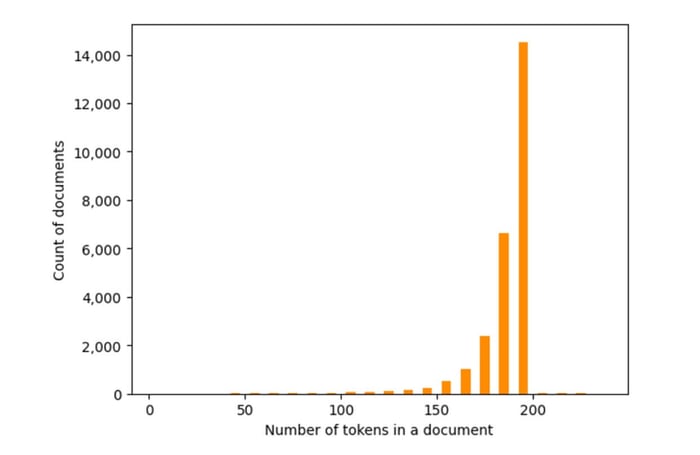
También deberías tomarte un momento para mirar algunos de los documentos para convencerte de que todo está funcionando bien antes de poder realizar el fine-tuning de un LLM mediante tus textos. Y, mientras estás allí, haz un viaje por el camino de los recuerdos sacando a la luz textos aleatorios de tu pasado.
Mezcla y encriptación
He reordenado los documentos para el entrenamiento del fine-tuning de un LLM con dichos documentos. Obviamente, dentro de cada documento, los mensajes permanecen en el orden correcto.
random.seed(42) # por reproducibilidad
random.shuffle(data)Luego encripté todos los datos de texto. Esto no debería ser necesario, ya que los almacenaremos de forma privada en el centro Hugging Face. Pero quería ser más cauteloso para mantener seguro mi historial de mensajes de texto. Anota la clave; la usaremos en Google Colab después de descargar el conjunto de datos.
key = Fernet.generate_key()
print(key)
f = Fernet(key)
data = [f.encrypt(d.encode('utf-8')) for d in data]Elaboración del conjunto de datos y carga
A continuación, dividimos los datos en un conjunto de datos de prueba y de entrenamiento, y reservamos el 5 % de los datos para la evaluación.
split = int(0.95 * len(data))
train, test = data[:split], data[split:]Luego convertimos esto al formato DatasetDict para Hugging Face:
from datasets import Dataset, DatasetDict
train_dataset = Dataset.from_dict({'text': train})
test_dataset = Dataset.from_dict({'text': test})
dataset = DatasetDict({'train': train_dataset, 'test': test_dataset})Iniciamos sesión en Hugging Face en el cuaderno de Python siguiendo las instrucciones de la Parte 1 y nos aseguramos de que nuestro token nos otorga permiso para escribir. Luego lo subimos a Hugging Face Hug mediante:
dataset.push_to_hub(DATA_NAME, private=True)Ahora deberías admirar tu trabajo iniciando sesión en Hugging Face y haciendo clic en tu página de perfil. Encontrarás tu nuevo y espectacular conjunto de datos esperándote. En la próxima entrega, volveremos a Google Colab, accederemos a este conjunto de datos y comenzaremos a ajustarlo. La próxima publicación de cómo realizar el fine-tuning de un LLM mediante tus textos está aquí.
¿Aún no estás inscrito en el curso completo?

Accede a todo el contenido del curso Ingeniería de LLMs e IA Generativa y domina las técnicas más avanzadas de IA generativa. ¡No pierdas esta oportunidad para transformar tu carrera profesional! 🎓
Apúntate al curso ahora¡Nos vemos en clase!


