¡Por fin, es hora de ajustar tu propio LLM! Preparamos tu conjunto de datos la semana pasada, y ahora estás perfectamente listo para ajustar tu propio LLM Llama 2 con tus mensajes de texto, como hice yo durante las vacaciones en el post original. Estamos utilizando QLoRA, y esta semana escribiremos más código que en cualquiera de las entregas anteriores. ¡Manos a la obra!
Recuerda que este es un post traducido originalmente del autor en inglés Edward Donner con quien hemos trabajado codo con codo para portar al castellano el curso de LLMs disponible en Frogames Formación.
¿Aún no estás inscrito en el curso completo?

Accede a todo el contenido del curso Ingeniería de LLMs e IA Generativa y domina las técnicas más avanzadas de IA generativa. ¡No pierdas esta oportunidad para transformar tu carrera profesional! 🎓
Apúntate al curso ahoraQLoRA es un enfoque altamente eficiente para ajustar tu propio LLM que te permite entrenar con una sola GPU, y se ha vuelto omnipresente para este tipo de proyectos. Combina dos técnicas:
- Cuantización, es decir, usar un LLM con precisión de pesos reducida a 4 bits.
- LoRA (adaptación de bajo rango para LLMs), que congela los pesos del modelo e inyecta nuevas capas, reduciendo enormemente la cantidad de pesos a entrenar.
Puedes encontrar más información sobre QLoRA en la lista de lectura al final del primer post. En este punto, vuelve a Google Colab (o equivalente) y comienza con algunas instalaciones e importaciones. Te recomiendo usar una instancia con GPU V100.
# instalar
!pip install -q torch peft bitsandbytes transformers trl accelerate sentencepiece cryptography wandb
# importar
import torch
from datasets import load_dataset, Dataset, DatasetDict
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline
)
from peft import LoraConfig
from trl import SFTTrainer
from cryptography.fernet import Fernet
from getpass import getpass
from huggingface_hub import notebook_login
import os
import wandbHiperparámetros
Buscar hiperparámetros es una actividad extraña y desconcertante, llena de trampas, obstáculos y madrigueras, con solo ocasionales momentos de eureka. El enfoque cuidadoso es comenzar cambiando un parámetro a la vez. Lamentablemente, carezco de la paciencia y el autocontrol para hacer esto, terminando por ajustar un montón de parámetros a la vez por capricho, y luego teniendo que volver atrás y repetir cuando me enfrento a resultados contradictorios.
La buena noticia: he pasado por este doloroso ejercicio por ti, y he salido con hiperparámetros que funcionaron bien, al menos para mi conjunto de datos. Te sugeriría que los tomes como punto de partida. Crucemos los dedos para que también funcionen bien para ti desde el principio.
# configuración
DATA_NAME = 'tu-usuario-de-hf/messagesv1'
PROJECT_NAME = 'messages'
RUN_NAME = 'v1'
MAX_SEQ_LENGTH = 200
BASE_MODEL_NAME = "meta-llama/Llama-2-7b-chat-hf" # Prueba 13b más tarde
REFINED_MODEL_NAME = f"tu-usuario-de-hf/{PROJECT_NAME}-{RUN_NAME}"
# HIPERPARAMETROS
LORA_ALPHA = 64
LORA_R = 32
LORA_DROPOUT = 0.1
BATCH_SIZE = 1
GRADIENT_ACCUMULATION_STEPS = 4
LEARNING_RATE = 2e-4
LR_SCHEDULER_TYPE = 'cosine'
WEIGHT_DECAY = 0.001
TARGET_MODULES = ["q_proj", "v_proj", "k_proj", "o_proj", "gate_proj", "up_proj", "down_proj"]
# MÁS CONFIGURACIONES
STEPS = 100
SAVE_STEPS = 500
EVAL_STEPS = 1000Explicación de los Hiperparámetros
Aquí tienes descripciones breves de los hiperparámetros y los valores con los que terminé para ajustar tu propio LLM para que hable como tú:
- LORA_ALPHA: este es un factor que escala las matrices de pesos inyectadas de LoRA; la regla general es que debería ser el doble del siguiente hiperparámetro,
r. - LORA_R: este es el número de dimensiones en las matrices de pesos de LoRA. Muchos ejemplos que he visto tienen
LORA_ALPHA=32yLORA_R=16. Empecé con eso, pero encontré que estos valores más altos funcionaron mejor, quizás debido a la cantidad de mis datos de entrenamiento. Deberías probar ambos. Nota que valores más altos derincrementan el tiempo de entrenamiento. - LORA_DROPOUT: esta es la probabilidad de dropout utilizada en las capas de LoRA; 0.1 parece ser lo más común, pero también se usa 0.05. Probé ambos, y 0.1 funcionó mejor.
- BATCH_SIZE: no tenía muchas opciones aquí; me quedé sin memoria de GPU en la V100 de 16 GB si intentaba un tamaño de lote mayor que 1.
- GRADIENT_ACCUMULATION_STEPS: acumular gradientes durante 4 pasos de lote pareció funcionar bien.
- LEARNING RATE, LR_SCHEDULER_TYPE, WEIGHT_DECAY: puedes visualizar el efecto de estos en la tasa de aprendizaje (Learning Rate) durante el entrenamiento en Weights & Biases. Encontré que estas configuraciones (que disminuyen la tasa de aprendizaje por un factor de 10 durante el entrenamiento) funcionaron mejor que
2e-4o2e-5como tasa de aprendizaje. - TARGET_MODULES: los módulos específicos a los que se debe apuntar en la arquitectura del modelo para LoRA. Esta es la elección más común: todas las capas lineales. En algunas situaciones, también se incluye
lm_headcuando buscas ajustar el modelo en el lenguaje de entrada, lo cual no debería ser nuestro caso.
A continuación, inicia sesión en Hugging Face y en Weights & Biases utilizando tus claves:
notebook_login() wandb_key = getpass("Enter Weights & Biases Key") wandb.login(key=wandb_key, relogin=True) # Configurar el proyecto en wandb os.environ["WANDB_PROJECT"] = PROJECT_NAME # Guardamos el checkpoint del modelo en wandb os.environ["WANDB_LOG_MODEL"] = "true" # Configuración watch a false para registros más rápidos os.environ["WANDB_WATCH"] = "false"
Carga y Encripta tus mensajes
Ahora puedes cargar tus mensajes desde Hugging Face y descifrarlos usando la misma clave. Este código imprime la estructura del conjunto de datos y un ejemplo; deberías verificar que todo se ve bien antes de ajustar tu propio LLM para que hable como tú.
# Cargamos el dataset desde Hugging Face
encrypted_data = load_dataset(DATA_NAME)
# Lo descodificamos
key = getpass("Introduce la clave de encriptación").encode()
f = Fernet(key)
decrypted_data = {'train':[], 'test':[]}
for split_name, split_list in decrypted_data.items():
split = encrypted_data[split_name]
for datapoint in split:
old = datapoint['text']
split_list.append(f.decrypt(old).decode('utf-8'))
# Regresamos el dataset
train_dataset = Dataset.from_dict({'text':decrypted_data['train']})
test_dataset = Dataset.from_dict({'text':decrypted_data['test']})
data = DatasetDict({'train':train_dataset, 'test':test_dataset})
print(data)
print(data['train'][0])
print(data['test'][0])Hora del espectáculo
Hemos llegado al momento de la verdad: vas a ajustar tu propio LLM para que hable como tú. Primero cargamos el modelo base de Llama 2 cuantizado para el entrenamiento:
# Nombres del Modelo y tokenizador
base_model_name = BASE_MODEL_NAME
refined_model = REFINED_MODEL_NAME
# Tokenizador
llama_tokenizer = AutoTokenizer.from_pretrained(base_model_name, trust_remote_code=True)
llama_tokenizer.pad_token = llama_tokenizer.eos_token
llama_tokenizer.padding_side = "right"
# Configuración Quantización
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True
)
# Modelo
base_model = AutoModelForCausalLM.from_pretrained(
base_model_name,
quantization_config=quant_config,
device_map="auto"
)
base_model.config.use_cache = False
base_model.config.pretraining_tp = 1Finalmente, ejecutamos el ajuste fino con LoRA en el modelo cuantizado. Si esto agota la memoria, intenta reducir el hiperparámetro **LoRA r** (y ajusta **alpha** por el mismo factor) y limita los módulos objetivo.
# LoRA Config
peft_parameters = LoraConfig(
lora_alpha=LORA_ALPHA,
lora_dropout=LORA_DROPOUT,
r=LORA_R,
bias="none",
task_type="CAUSAL_LM",
target_modules=TARGET_MODULES,
)
# Training Params
train_params = TrainingArguments(
output_dir=REFINED_MODEL_NAME,
num_train_epochs=1,
per_device_train_batch_size=BATCH_SIZE,
per_device_eval_batch_size=1,
evaluation_strategy="steps",
eval_steps=EVAL_STEPS,
gradient_accumulation_steps=GRADIENT_ACCUMULATION_STEPS,
optim="paged_adamw_32bit",
save_steps=SAVE_STEPS,
save_total_limit=10, # to avoid running out of disk space!
logging_steps=STEPS,
learning_rate=LEARNING_RATE,
weight_decay=WEIGHT_DECAY,
fp16=False,
bf16=False,
max_grad_norm=0.3,
max_steps=-1,
warmup_ratio=0.03,
group_by_length=True,
lr_scheduler_type=LR_SCHEDULER_TYPE,
report_to="wandb",
run_name=RUN_NAME,
push_to_hub=True,
hub_model_id=REFINED_MODEL_NAME,
hub_strategy="end",
hub_private_repo=True
)
# Trainer
fine_tuning = SFTTrainer(
model=base_model,
train_dataset=data['train'],
eval_dataset=data['test'],
peft_config=peft_parameters,
dataset_text_field="text",
tokenizer=llama_tokenizer,
max_seq_length=MAX_SEQ_LENGTH,
args=train_params
)
# Training
fine_tuning.train()
# Save Model
fine_tuning.model.save_pretrained(refined_model)
# Push model
fine_tuning.model.push_to_hub(REFINED_MODEL_NAME, private=True)Cada una de estas sesiones de entrenamiento me tomó unas 8 horas, por lo que normalmente las dejaba ejecutándose durante la noche. A la mañana siguiente, me despertaba encantado de encontrar mi nuevo modelo cargado en Hugging Face.
Seguimiento en Weights & Biases
Mientras esto se ejecuta, deberías iniciar sesión en W&B y seguir el progreso en tiempo real. Deberías observar cómo la pérdida de entrenamiento disminuye rápidamente después de los primeros pasos de entrenamiento. En algunos casos, logré notar un progreso constante hasta casi el final del entrenamiento.
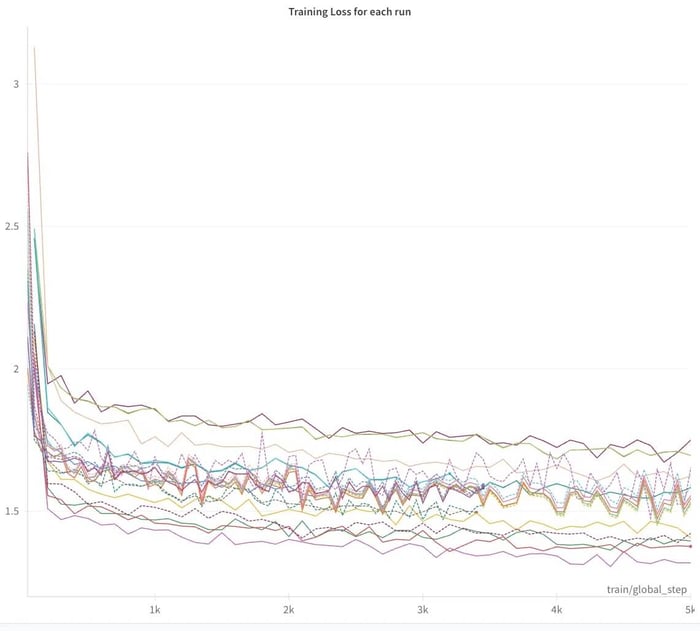
Solo entrené durante 1 época; intenté realizar una segunda época en una ocasión, pero inmediatamente apareció un sobreajuste significativo, con la pérdida de evaluación aumentando drásticamente.
⚠️ Nota de precaución: Puede ser muy tentador seguir ajustando los hiperparámetros para observar cómo disminuye la pérdida cuando te dejas a ajustar tu propio LLM para que hable como tú. Sin embargo, esto puede ser engañoso. Encontré situaciones en las que la pérdida disminuía, pero la calidad de los resultados empeoraba notablemente.
Conclusión: Al final, tras ajustar tu propio LLM para que hable como tú, necesitas evaluar los resultados de la generación de texto para determinar qué tan bien está funcionando tu modelo.
Y con eso hacemos la transición perfecta a la siguiente y última parte, donde probarás tu modelo. 🧪 Generaremos mensajes de texto, actuando como tú o como tus amigos. ¡Hablar contigo mismo puede ser una experiencia realmente alucinante! Estoy bastante seguro de que encontrarás esto tan divertido como yo, y valdrá la pena el tiempo invertido y los $100. 🤑 La entrega final está aquí. 🚀
¡Nos vemos en clase!