

Hemos iniciado este mes de abril con muchos proyectos en curso, de los cuales pronto conocerás. En esa ocasión, traemos uno de los artículos del equipo de SuperDataScience, en el cual podrás aprender un poco más sobre cómo aprenden las redes neuronales artificiales. Si estas interesado en el Machine Learning, el Deep Learning y la Inteligencia Artificial en general, debes echarle un vistazo.
¡Disfrútalo!
¿Cómo aprenden las redes neuronales artificiales?
Ahora que hemos visto las redes neuronales artificiales en acción es hora de entrar en un aprendizaje profundo y descubrir cómo aprenden.
Hay dos enfoques fundamentalmente diferentes para obtener el resultado deseado de tu programa.
Hardcoding
Aquí es donde se indican las normas y resultados específicos del programa, y luego los guía a lo largo de todo el proceso, dando cuenta de todas las opciones posibles con las que el programa tendrá que lidiar. Es un proceso más involucrado con más interacción entre el programador y el programa.
El otro enfoque es el que hemos estado estudiando hasta ahora.
Red neuronal
Con una red neural, se crea la facilidad para que el programa entienda lo que necesita hacer de forma independiente. Proporcionas las entradas, declaras los resultados deseados y dejas que trabaje a su manera de uno a otro.
La diferencia entre estos enfoques es la siguiente. El hardcoding es el hombre que conduce su coche de un punto a otro, usando señales de tráfico y un mapa para realizar su propio camino hacia su destino. Las redes neuronales artificiales son Teslas autoconducidos.
Volvamos a revisar la tierra vieja conocida antes de que aremos en tierra fresca.
Aquí hay una red neuronal básica que hemos visto muchas veces hasta ahora:
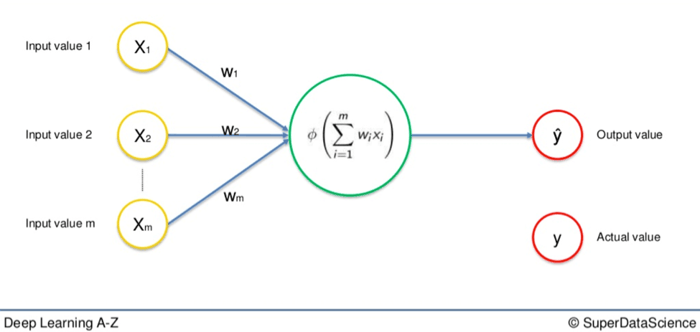
Tienes la fila única de variables de entrada a la izquierda. Las flechas que representan las sinapsis ponderadas van a la gran neurona del medio. Y a la derecha, tienes el valor de salida. Esto se llama red neuronal de alimentación de una sola capa.
Como puedes ver, el valor de salida de arriba se representa como Y. Este es el valor real. Vamos a reemplazarlo con Ŷ, que representa el valor de salida.
La diferencia entre Y y Ŷ es el centro de todo este proceso.
Cuando las variables de entrada van a lo largo de las sinapsis y en la neurona, donde se aplica una función de activación, los datos resultantes son el valor de salida, Ŷ.
Para que nuestra red aprenda, necesitamos comparar el valor de salida con el valor real. Habrá una diferencia entre los dos.
La función de coste
Luego aplicamos lo que se llama una función de costo, que es la mitad de la diferencia cuadrada entre el valor de salida y el valor real. Esta es sólo una de las funciones de costo comúnmente utilizadas. Hay muchas. Aplicaremos esta en particular en nuestros cálculos.
La función de costo nos dice el error en nuestra predicción.
Nuestro objetivo es minimizar la función de costo. Cuanto más baja sea la función de costo, más se acerca Ŷ a Y, y por lo tanto, más se acerca nuestro valor de salida a nuestro valor real. Una función de costo más baja significa mayor precisión para nuestra red.
Una vez que tenemos nuestra función de costo, comienza un proceso de reciclaje.
Devolvemos los datos resultantes a través de toda la red neuronal. Las sinapsis ponderadas que conectan las variables de entrada a la neurona es lo único sobre lo que tenemos control.
Mientras exista una disparidad entre Y y Ŷ, tendremos que ajustar esos valores. Una vez que los ajustemos un poco, volvemos a ejecutar la red. Se producirá un nuevo valor para la función de coste, con suerte, más pequeño que el anterior.
Aclara y repite
Tenemos que repetir esto hasta que reduzcamos la función de coste a un número lo más pequeño posible, lo más cercano al 0.
Cuando el valor de salida y el valor real casi se igualan, sabemos que tenemos valores óptimos y por lo tanto podemos proceder a la fase de prueba, o fase de aplicación.
Ejemplo
Digamos que tenemos tres valores de entrada.
- Horas de estudio
- Horas de sueño
- El resultado en una prueba de mitad de semestre
Basándonos en estas variables estamos tratando de calcular el resultado en un próximo examen. Digamos que el resultado del examen es el 93%. Ese sería nuestro valor real, Y.
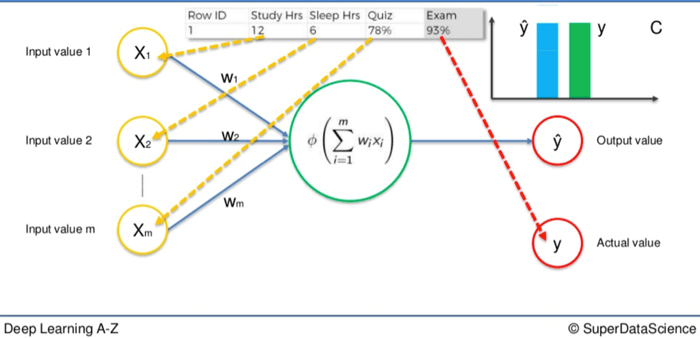
Alimentamos las variables a través de las sinapsis ponderadas y la neurona para calcular nuestro valor de salida, Ŷ.
Luego se aplica la función de coste y los datos van a la inversa a través de la red neuronal.
Si hay una disparidad entre Y y Ŷ entonces los valores ponderados se ajustarán y el proceso puede comenzar de nuevo. Se aclara y se repite hasta que la función de coste se minimiza.
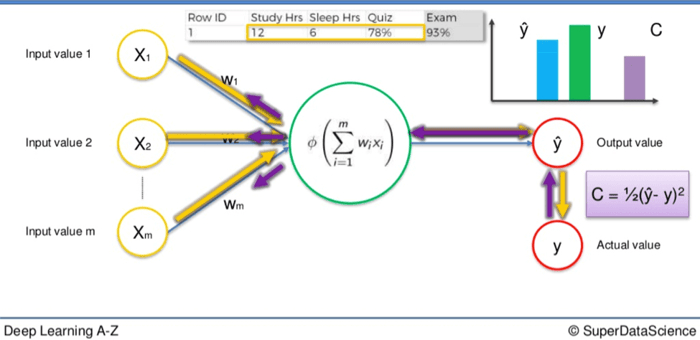
En este ejemplo eso significaría que nuestro valor de salida sería igual al valor real del 93% de la puntuación del test.
Recuerda, las variables de entrada no cambian.
Sólo el valor de la sinapsis se altera después de que la función de costo entra en juego. Para darte una idea del alcance potencial de este proceso podemos ampliar este ejemplo. La simple red neuronal citada anteriormente podría aplicarse a un solo estudiante.
Más grande
¿Y si quisieras aplicar este proceso a toda una clase? Simplemente necesitarías duplicar estas redes más pequeñas y repetir el proceso de nuevo.
Sin embargo, una vez que lo hagamos, no tendremos un número de redes neuronales artificiales más pequeñas procesando por separado una al lado de la otra.
En realidad se fusionan para formar una sola red neuronal mucho más grande.
Así que cuando vuelvas a pasar por el proceso de minimizar la diferencia entre Y y Ŷ para una clase entera, la fase de función de costo al final se ajustará para cada estudiante simultáneamente.
Si tienes treinta estudiantes, la comparación Y / Ŷ ocurrirá treinta veces en cada red más pequeña pero la función de costo se aplicará a todos ellos juntos.
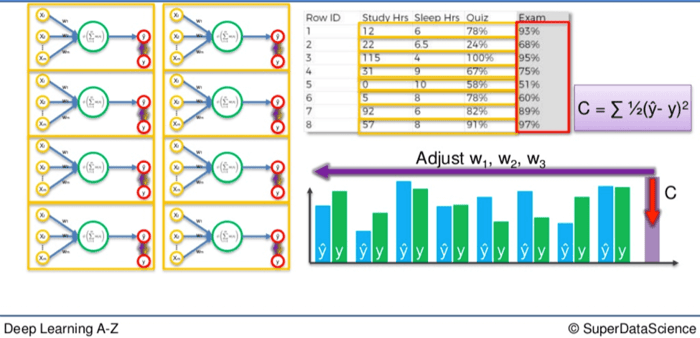
Como resultado, los valores de cada estudiante se ajustarán en consecuencia.
Si deseas leer la versión original en inglés, haz clic aquí.

Aprende mucho más con nuestros cursos
Si deseas aprender mas sobre redes neuronales artificiales, te invitamos a que disfrutes con los mejores cursos de Juan Gabriel Gomila en Frogames Formación:
- Curso completo de Machine Learning: Data Science con RStudio
- Curso completo de Machine Learning: Data Science en Python
- Deep Learning con TensorFlow para Machine Learning e IA
- Machine Learning de la A a la Z: R y Python para data science
- Deep Learning de A a Z: redes neuronales en Python desde cero
- Probabilidad para Machine Learning y Big data con R y Python
- Estadística inferencial para Machine Learning con R y Python
De igual modo, puedes acceder a nuestra Tienda Online para ver más información sobre todos los cursos de Machine Learning.
¡Nos vemos en clase!


